Latest Microsoft Exam Practice Questions, DP-200, DP-201 Exam Tips For Free

What are the best online course and practice tests set to prepare for Microsoft Certified Professional Azure Data Engineer Associate Certification (DP-200 and DP-201)? (First: Exam practice test, Second: leads4pass Microsoft expert.) You can get free Microsoft exam practice test questions here. Or choose: https://www.leads4pass.com/microsoft.html Study hard to pass the exam easily!
Table of Contents:
- Latest Microsoft DP-200 List
- Latest Microsoft DP-201 List
- leads4pass Year-round Discount Code
- What are the advantages of leads4pass?
Latest Microsoft Exam questions
Latest Microsoft DP-200 List
Microsoft DP-200 Exam Video
Exam DP-200: Implementing an Azure Data Solution: https://docs.microsoft.com/en-us/learn/certifications/exams/dp-200
Candidates for this exam are Microsoft Azure data engineers who collaborate with business stakeholders to identify and meet the data requirements to implement data solutions that use Azure data services.
Azure data engineers are responsible for data-related implementation tasks that include provisioning data storage services, ingesting streaming and batch data, transforming data, implementing security requirements, implementing data retention policies, identifying performance bottlenecks, and accessing external data sources.
Candidates for this exam must be able to implement data solutions that use the following Azure services: Azure Cosmos DB, Azure SQL Database, Azure Synapse Analytics (formerly Azure SQL DW), Azure Data Lake Storage, Azure Data Factory, Azure Stream Analytics, Azure Databricks, and Azure Blob storage.
Latest updates Microsoft DP-200 exam practice questions(1-10)
QUESTION 1
A company plans to use Azure Storage for file storage purposes. Compliance rules require:
A single storage account to store all operations including reads, writes and deletes Retention of an on-premises copy of
historical operations
You need to configure the storage account.
Which two actions should you perform? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A. Configure the storage account to log read, write and delete operations for service type Blob
B. Use the AzCopy tool to download log data from $logs/blob
C. Configure the storage account to log read, write and delete operations for service-type table
D. Use the storage client to download log data from $logs/table
E. Configure the storage account to log read, write and delete operations for service type queue
Correct Answer: AB
Storage Logging logs request data in a set of blobs in a blob container named $logs in your storage account. This
container does not show up if you list all the blob containers in your account but you can see its contents if you access it
directly.
To view and analyze your log data, you should download the blobs that contain the log data you are interested in to a
local machine. Many storage-browsing tools enable you to download blobs from your storage account; you can also use
the Azure Storage team provided command-line Azure Copy Tool (AzCopy) to download your log data.
References: https://docs.microsoft.com/en-us/rest/api/storageservices/enabling-storage-logging-and-accessing-log-data
QUESTION 2
You need to develop a pipeline for processing data. The pipeline must meet the following requirements.
-Scale up and down resources for cost reduction.
–
Use an in-memory data processing engine to speed up ETL and machine learning operations.
–
Use streaming capabilities.
-Provide the ability to code in SQL, Python, Scala, and R.
–
Integrate workspace collaboration with Git. What should you use?
A.
HDInsight Spark Cluster
B.
Azure Stream Analytics
C.
HDInsight Hadoop Cluster
D.
Azure SQL Data Warehouse
Correct Answer: B
QUESTION 3
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains
a unique solution. Determine whether the solution meets the stated goals.
You develop a data ingestion process that will import data to a Microsoft Azure SQL Data Warehouse. The data to be
ingested resides in parquet files stored in an Azure Data lake Gen 2 storage account.
You need to load the data from the Azure Data Lake Gen 2 storage account into the Azure SQL Data Warehouse.
Solution;
1.
Create an external data source pointing to the Azure Data Lake Gen 2 storage account.
2.
Create an external tile format and external table using the external data source.
3.
Load the data using the CREATE TABLE AS SELECT statement. Does the solution meet the goal?
A. Yes
B. No
Correct Answer: A
QUESTION 4
You need to provision the polling data storage account.
How should you configure the storage account? To answer, drag the appropriate Configuration Value to the correct
Setting. Each Configuration Value may be used once, more than once, or not at all. You may need to drag the split bar
between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Select and Place: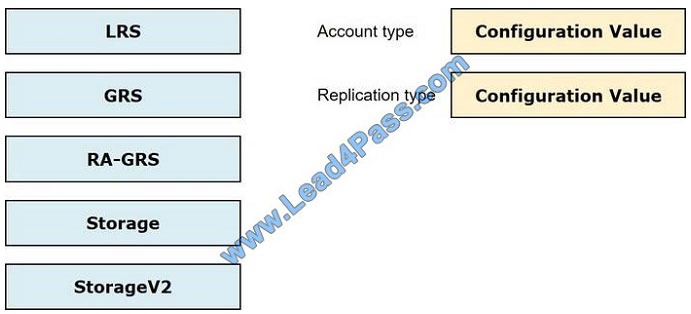
Correct Answer:
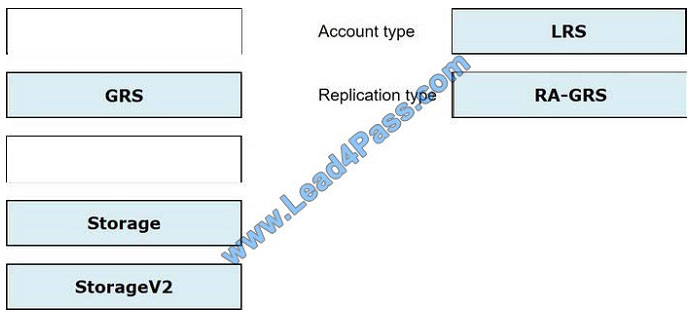
QUESTION 5
Your company plans to create an event processing engine to handle streaming data from Twitter.
The data engineering team uses Azure Event Hubs to ingest the streaming data.
You need to implement a solution that uses Azure Databricks to receive the streaming data from the Azure Event Hubs.
Which three actions should you recommend be performed in sequence? To answer, move the appropriate actions from
the list of actions to the answer area and arrange them in the correct order.
Select and Place: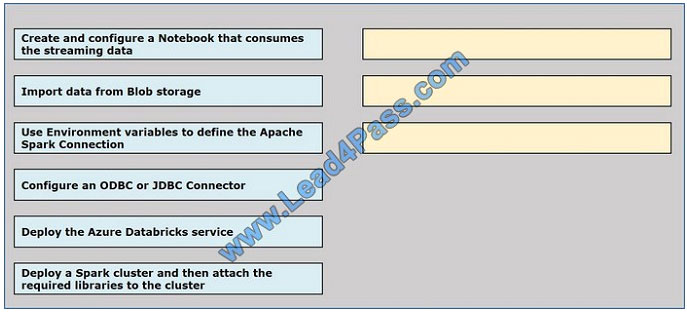
Correct Answer:
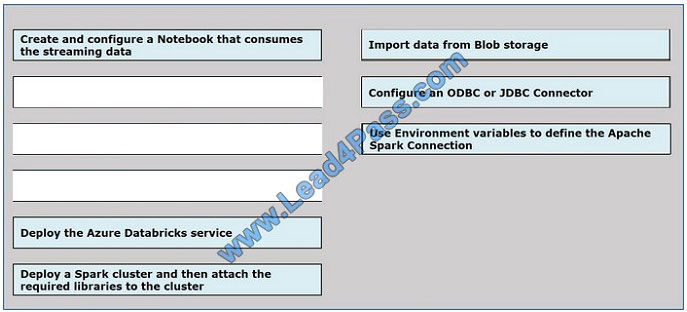
QUESTION 6
The data engineering team manages Azure HDInsight clusters. The team spends a large amount of time creating and
destroying clusters daily because most of the data pipeline process runs in minutes. You need to implement a solution
that deploys multiple HDInsight clusters with minimal effort.
What should you implement?
A. Azure Databricks
B. Azure Traffic Manager
C. Azure Resource Manager templates
D. Ambari web user interface
Correct Answer: C
A Resource Manager template makes it easy to create the following resources for your application in a single,
coordinated operation:
HDInsight clusters and their dependent resources (such as the default storage account).
Other resources (such as Azure SQL Database to use Apache Sqoop).
In the template, you define the resources that are needed for the application. You also specify deployment parameters
to input values for different environments. The template consists of JSON and expressions that you use to construct
values for your deployment.
References:
https://docs.microsoft.com/en-us/azure/hdinsight/hdinsight-hadoop-create-linux-clusters-arm-templates
QUESTION 7
You are developing the data platform for a global retail company. The company operates during normal working hours in
each region. The analytical database is used once a week for building sales projections.
Each region maintains its own private virtual network.
Building the sales projections is very resource intensive are generates upwards of 20 terabytes (TB) of data.
Microsoft Azure SQL Databases must be provisioned.
Database provisioning must maximize performance and minimize cost
The daily sales for each region must be stored in an Azure SQL Database instance Once a day, the data for all regions
must be loaded in an analytical Azure SQL Database instance
You need to provision Azure SQL database instances.
How should you provision the database instances? To answer, drag the appropriate Azure SQL products to the correct
databases. Each Azure SQL product may be used once, more than once, or not at all. You may need to drag the split
bar
between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Select and Place: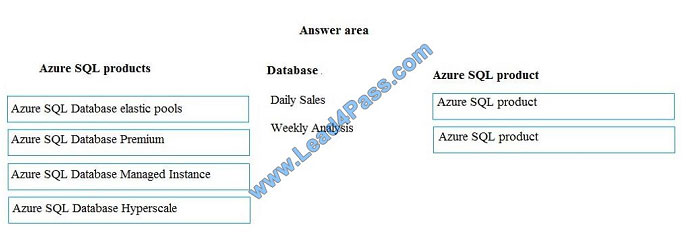
Correct Answer:

Box 1: Azure SQL Database elastic pools
SQL Database elastic pools are a simple, cost-effective solution for managing and scaling multiple databases that have
varying and unpredictable usage demands. The databases in an elastic pool are on a single Azure SQL Database
server
and share a set number of resources at a set price. Elastic pools in Azure SQL Database enable SaaS developers to
optimize the price performance for a group of databases within a prescribed budget while delivering performance
elasticity
for each database.
Box 2: Azure SQL Database Hyperscale
A Hyperscale database is an Azure SQL database in the Hyperscale service tier that is backed by the Hyperscale scale-
out storage technology. A Hyperscale database supports up to 100 TB of data and provides high throughput and
performance, as well as rapid scaling to adapt to the workload requirements. Scaling is transparent to the application
QUESTION 8
A company plans to use Platform-as-a-Service (PaaS) to create the new data pipeline process. The process must meet
the following requirements.
Ingest:
– Access multiple data sources
– Provide the ability to orchestrate workflow
– Provide the capability to run SQL Server Integration Services packages.
Store:
– Optimize storage for big data workloads.
– Provide encryption of data at rest.
– Operate with no size limits.
Prepare and Train:
– Provide a fully-managed and interactive workspace for exploration and visualization.
– Provide the ability to program in R, SQL, Python, Scala, and Java.
– Provide seamless user authentication with Azure Active Directory.
Model and Serve:
– Implement native columnar storage.
– Support for the SQL language
– Provide support for structured streaming.
You need to build the data integration pipeline.
Which technologies should you use? To answer, select the appropriate options in the answer area.
Hot Area:
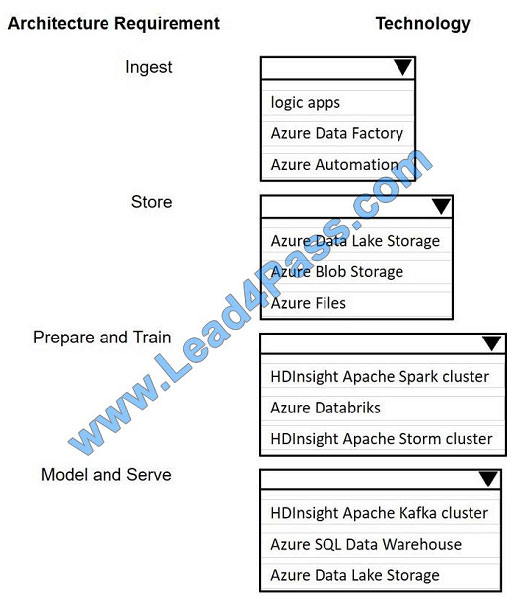
Correct Answer:
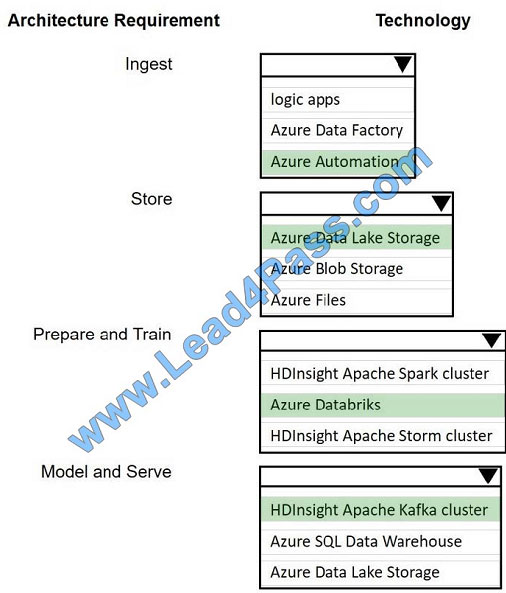
QUESTION 9
You develop data engineering solutions for a company. You must migrate data from Microsoft Azure Blob storage to an
Azure SQL Data Warehouse for further transformation. You need to implement the solution. Which four actions should
you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and
arrange them in the correct order.
Select and Place: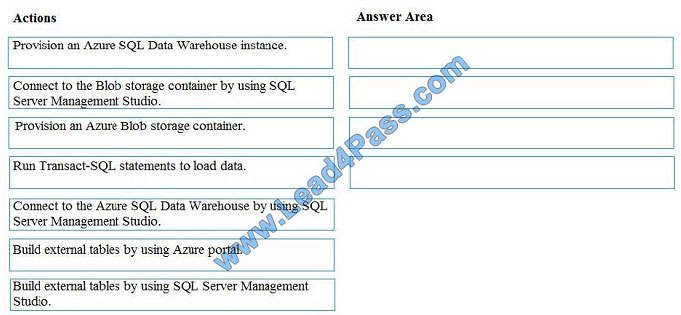
Correct Answer:

QUESTION 10
You need to ensure that Azure Data Factory pipelines can be deployed. How should you configure authentication and
authorization for deployments? To answer, select the appropriate options in the answer choices. NOTE: Each correct
selection is worth one point.
Hot Area:
Correct Answer:

Explanation/Reference:
The way you control access to resources using RBAC is to create role assignments. This is a key concept to understand
[PDF] Free Microsoft DP-200 pdf dumps download from Google Drive: https://drive.google.com/open?id=1H70200WCZAc8N43RdlP4JVsNXdOm0D2U
Full Microsoft DP-200 exam practice questions: https://www.leads4pass.com/dp-200.html (Total Questions: 159 Q&A)
Latest Microsoft DP-201 List
Microsoft DP-201 Exam Video
Exam DP-201: Designing an Azure Data Solution:https://docs.microsoft.com/en-us/learn/certifications/exams/DP-201
Candidates for this exam are Microsoft Azure data engineers who collaborate with business stakeholders to identify and meet the data requirements to design data solutions that use Azure data services.
Azure data engineers are responsible for data-related tasks that include designing Azure data storage solutions that use relational and non-relational data stores, batch and real-time data processing solutions, and data security and compliance solutions.
Candidates for this exam must design data solutions that use the following Azure services: Azure Cosmos DB, Azure SQL Database, Azure SQL Data Warehouse, Azure Data Lake Storage, Azure Data Factory, Azure Stream Analytics, Azure Databricks, and Azure Blob storage.
Latest updates Microsoft DP-201 exam practice questions (1-10)
QUESTION 1
You have an on-premises data warehouse that includes the following fact tables. Both tables have the following
columns: DataKey, ProductKey, RegionKey. There are 120 unique product keys and 65 unique region keys.
Queries that use the data warehouse take a long time to complete.
You plan to migrate the solution to use Azure SQL Data Warehouse. You need to ensure that the Azure-based solution
optimizes query performance and minimizes processing skew.
What should you recommend? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Correct Answer:
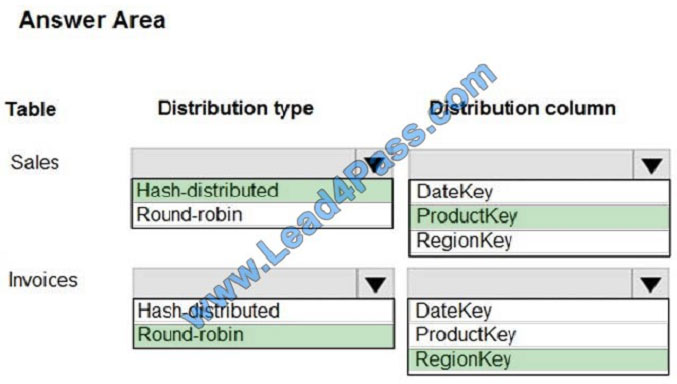
Box 1: Hash-distributed
Box 2: ProductKey
ProductKey is used extensively in joins.
Hash-distributed tables improve query performance on large fact tables.
Box 3: Round-robin
Box 4: RegionKey
Round-robin tables are useful for improving loading speed.
Consider using the round-robin distribution for your table in the following scenarios:
When getting started as a simple starting point since it is the default
If there is no obvious joining key
If there is not good candidate column for hash distributing the table
If the table does not share a common join key with other tables
If the join is less significant than other joins in the query
When the table is a temporary staging table
Note: A distributed table appears as a single table, but the rows are actually stored across 60 distributions. The rows are
distributed with a hash or round-robin algorithm.
References:
https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-tables-distribute
QUESTION 2
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains
a unique solution that might meet the stated goals. Some question sets might have more than one correct solution,
while
others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not
appear in the review screen.
A company is developing a solution to manage inventory data for a group of automotive repair shops. The solution will
use Azure SQL Data Warehouse as the data store.
Shops will upload data every 10 days.
Data corruption checks must run each time data is uploaded. If corruption is detected, the corrupted data must be
removed.
You need to ensure that upload processes and data corruption checks do not impact reporting and analytics processes
that use the data warehouse.
Proposed solution: Configure database-level auditing in Azure SQL Data Warehouse and set retention to 10 days.
Does the solution meet the goal?
A. Yes
B. No
Correct Answer: B
Instead, create a user-defined restore point before data is uploaded. Delete the restore point after data corruption
checks complete.
References: https://docs.microsoft.com/en-us/azure/sql-data-warehouse/backup-and-restore
QUESTION 3
You need to design network access to the SQL Server data.
What should you recommend? To answer, select the appropriate options in the answer area. NOTE: Each correct
selection is worth one point.
Hot Area:
Correct Answer:

Box 1: 8080
1433 is the default port, but we must change it as CONT_SQL3 must not communicate over the default ports. Because
port 1433 is the known standard for SQL Server, some organizations specify that the SQL Server port number should
be
changed to enhance security.
Box 2: SQL Server Configuration Manager
You can configure an instance of the SQL Server Database Engine to listen on a specific fixed port by using the SQL
Server Configuration Manager.
References:
https://docs.microsoft.com/en-us/sql/database-engine/configure-windows/configure-a-server-to-listen-on-a-specific-tcp-port?view=sql-server-2017
QUESTION 4
You need to design a backup solution for the processed customer data.
What should you include in the design?
A. AzCopy
B. AdlCopy
C. Geo-Redundancy
D. Geo-Replication
Correct Answer: C
Scenario: All data must be backed up in case disaster recovery is required.
Geo-redundant storage (GRS) is designed to provide at least 99.99999999999999% (16 9\\’s) durability of objects over
a given year by replicating your data to a secondary region that is hundreds of miles away from the primary region. If
your storage account has GRS enabled, then your data is durable even in the case of a complete regional outage or a
disaster in which the primary region isn\\’t recoverable.
References: https://docs.microsoft.com/en-us/azure/storage/common/storage-redundancy-grs
QUESTION 5
A company is designing a solution that uses Azure Databricks.
The solution must be resilient to regional Azure datacenter outages.
You need to recommend the redundancy type for the solution.
What should you recommend?
A. Read-access geo-redundant storage
B. Locally-redundant storage
C. Geo-redundant storage
D. Zone-redundant storage
Correct Answer: C
If your storage account has GRS enabled, then your data is durable even in the case of a complete regional outage or a
disaster in which the primary region isn\\’t recoverable.
References: https://medium.com/microsoftazure/data-durability-fault-tolerance-resilience-in-azure-databricks-95392982bac7
QUESTION 6
You are designing an Azure Data Factory pipeline for processing data. The pipeline will process data that is stored in
general-purpose standard Azure storage.
You need to ensure that the compute environment is created on-demand and removed when the process is completed.
Which type of activity should you recommend?
A. Databricks Python activity
B. Data Lake Analytics U-SQL activity
C. HDInsight Pig activity
D. Databricks Jar activity
Correct Answer: C
The HDInsight Pig activity in a Data Factory pipeline executes Pig queries on your own or on-demand HDInsight
cluster.
References: https://docs.microsoft.com/en-us/azure/data-factory/transform-data-using-hadoop-pig
QUESTION 7
You need to recommend a backup strategy for CONT_SQL1 and CONT_SQL2. What should you recommend?
A. Use AzCopy and store the data in Azure.
B. Configure Azure SQL Database long-term retention for all databases.
C. Configure Accelerated Database Recovery.
D. Use DWLoader.
Correct Answer: B
Scenario: The database backups have regulatory purposes and must be retained for seven years.
QUESTION 8
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains
a unique solution that might meet the stated goals. Some question sets might have more than one correct solution,
while
others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not
appear in the review screen.
You are designing an HDInsight/Hadoop cluster solution that uses Azure Data Lake Gen1 Storage.
The solution requires POSIX permissions and enables diagnostics logging for auditing.
You need to recommend solutions that optimize storage.
Proposed Solution: Implement compaction jobs to combine small files into larger files.
Does the solution meet the goal?
A. Yes
B. No
Correct Answer: A
Depending on what services and workloads are using the data, a good size to consider for files is 256 MB or greater. If
the file sizes cannot be batched when landing in Data Lake Storage Gen1, you can have a separate compaction job that
combines these files into larger ones.
Note: POSIX permissions and auditing in Data Lake Storage Gen1 comes with an overhead that becomes apparent
when working with numerous small files. As a best practice, you must batch your data into larger files versus writing
thousands or millions of small files to Data Lake Storage Gen1. Avoiding small file sizes can have multiple benefits,
such as: Lowering the authentication checks across multiple files Reduced open file connections Faster
copying/replication Fewer files to process when updating Data Lake Storage Gen1 POSIX permissions
References: https://docs.microsoft.com/en-us/azure/data-lake-store/data-lake-store-best-practices
QUESTION 9
A company has locations in North America and Europe. The company uses Azure SQL Database to support business
apps.
Employees must be able to access the app data in case of a region-wide outage. A multi-region availability solution is
needed with the following requirements:
Read-access to data in a secondary region must be available only in case of an outage of the primary region.
The Azure SQL Database compute and storage layers must be integrated and replicated together.
You need to design the multi-region high availability solution.
What should you recommend? To answer, select the appropriate values in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Correct Answer:

Box 1: Standard
The following table describes the types of storage accounts and their capabilities:
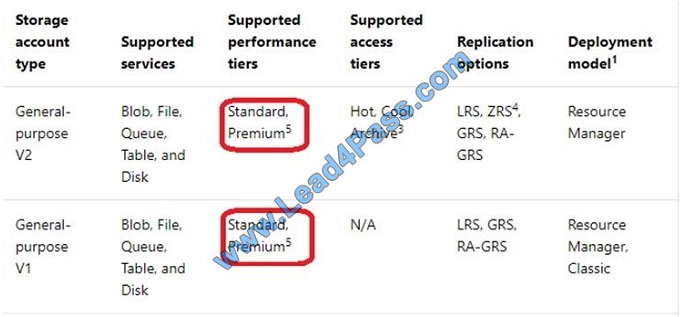
Box 2: Geo-redundant storage
If your storage account has GRS enabled, then your data is durable even in the case of a complete regional outage or a
disaster in which the primary region isn\\’t recoverable.
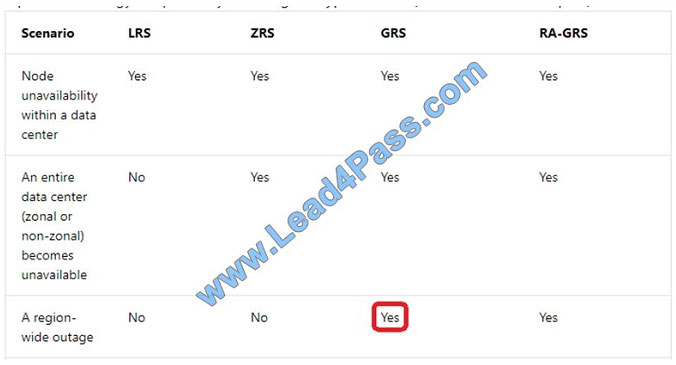
Note: If you opt for GRS, you have two related options to choose from:
GRS replicates your data to another data center in a secondary region, but that data is available to be read only if
Microsoft initiates a failover from the primary to secondary region. Read-access geo-redundant storage (RA-GRS) is
based on
GRS. RA-GRS replicates your data to another data center in a secondary region, and also provides you with the option
to read from the secondary region. With RA-GRS, you can read from the secondary region regardless of whether
Microsoft initiates a failover from the primary to secondary region.
References:
https://docs.microsoft.com/en-us/azure/storage/common/storage-introduction
https://docs.microsoft.com/en-us/azure/storage/common/storage-redundancy-grs
QUESTION 10
You are designing a solution for a company. The solution will use model training for objective classification.
You need to design the solution.
What should you recommend?
A. an Azure Cognitive Services application
B. a Spark Streaming job
C. interactive Spark queries
D. Power BI models
E. a Spark application that uses Spark MLib.
Correct Answer: E
Spark in SQL Server big data cluster enables AI and machine learning.
You can use Apache Spark MLlib to create a machine learning application to do simple predictive analysis on an open
dataset.
MLlib is a core Spark library that provides many utilities useful for machine learning tasks, including utilities that are
suitable for:
Classification
Regression
Clustering
Topic modeling
Singular value decomposition (SVD) and principal component analysis (PCA)
Hypothesis testing and calculating sample statistics
References:
https://docs.microsoft.com/en-us/azure/hdinsight/spark/apache-spark-machine-learning-mllib-ipython
[PDF] Free Microsoft DP-201 pdf dumps download from Google Drive: https://drive.google.com/open?id=1yqED9d-JympHFeYcm3BWSkK24lR2ggOR
Full Microsoft DP-201 exam practice questions: https://www.leads4pass.com/dp-201.html (Total Questions: 145 Q&A)
Related Microsoft Popular Exam resources
| title | youtube | Microsoft | leads4pass | leads4pass Total Questions | |
|---|---|---|---|---|---|
| Microsoft | leads4pass DP-200 dumps pdf | leads4pass DP-200 youtube | Implementing an Azure Data Solution | https://www.leads4pass.com/dp-200.html | 159 Q&A |
| leads4pass DP-201 dumps pdf | leads4pass DP-201 youtube | Designing an Azure Data Solution | https://www.leads4pass.com/dp-201.html | 145 Q&A |
leads4pass Year-round Discount Code

What are the advantages of leads4pass?
leads4pass employs the most authoritative exam specialists from Microsoft, Cisco, CompTIA, VMware, Oracle, etc. We update exam data throughout the year. Highest pass rate! We have a large user base. We are an industry leader! Choose leads4pass to pass the exam with ease!
Summarize:
It’s not easy to pass the Microsoft exam, but with accurate learning materials and proper practice, you can crack the exam with excellent results. https://www.leads4pass.com/microsoft.html provides you with the most relevant learning materials that you can use to help you prepare.